In diesem Tutorial möchten wir die Einfachheit von instantOLAP vorstellen. Sie können sich durch die Lektionen klicken oder das PDF herunterladen Dokument.
Mit 18 Klicks von Grund auf zu einem Bericht!
In dieser ersten Lektion erstellt eine einfache Konfiguration mit einer einzigen Dimension und eine einfache Abfrage basierend auf dieser Konfiguration.
Die KonfigurationAlle neuen Konfigurationen und Abfragen, die in diesem Lernprogramm erstellt wurden, sollten in einem eigenen Ordner abgelegt werden. Verwenden Sie das Menü „Neuen Ordner erstellen“, um einen neuen Unterordner im Repository zu erstellen. Um das Menü zu öffnen, verwenden Sie die rechte Maustaste im Stammordner des Repositorys.
Z.B. Benennen Sie den neuen Ordner „Tutorial“. Nachdem Sie die Schaltfläche „Okay“ gedrückt haben, erscheint der neue Ordner im Repository-Explorer.
Neue Konfigurationsdatei erstellen
Zunächst müssen Sie eine neue Konfiguration für Ihre Tutorial-Lektion erstellen. Eine Konfiguration definiert alle Dimensionen, Fakten und Cubes für die spätere Verwendung in Ihren Queries. Jede Abfrage bezieht sich auf genau eine Konfiguration.
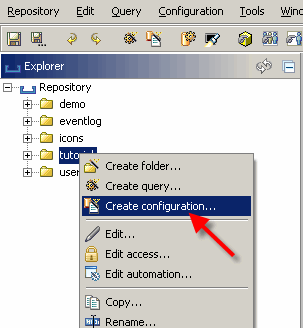
Verwenden Sie die Schaltfläche „Neue Konfiguration erstellen“, um eine neue, leere Konfiguration in Ihrem Stammordner zu erstellen. Diese Schaltfläche wird in der Symbolleiste oben in der Workbench platziert. Nach dem Drücken dieser Taste erscheint der Konfigurationsassistent:
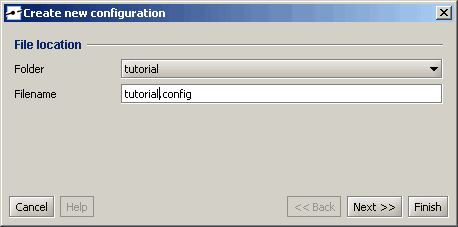
Füllen Sie den Konfigurationsdateinamen aus (z. B. „tutorial.config“ als Dateinamen für Ihre neue Konfiguration) und klicken Sie auf „Fertig stellen“. Ein neues Fenster wird geöffnet, in dem die neue Konfiguration angezeigt wird.
Datenbank hinzufügen

Ein weiterer Assistent wird angezeigt, der dieses Mal nach Eigenschaften für die Datenbankverbindung fragt. Es gibt zwei Möglichkeiten, um eine Datenbank in instantOLAP zu verbinden: Durch Verwendung einer vordefinierten Verbindung, die von Ihrem Anwendungsserver-Administrator bereitgestellt wird, oder mithilfe eines jdbc-Treibers. Wir werden die erste Methode verwenden, da es bereits eine Verbindung in der Standardinstallation von instantOLAP gibt.
Zunächst müssen Sie einen logischen Namen für Ihre Datenquelle angeben. Dieser Name muss nicht dem tatsächlichen Datenbanknamen entsprechen, er muss jedoch eindeutig sein, wenn Sie mehr als eine Datenquelle in Ihrer Konfiguration definieren. Z.B. Verwenden Sie „TUTORIAL“ als Name für die Datenquelle.
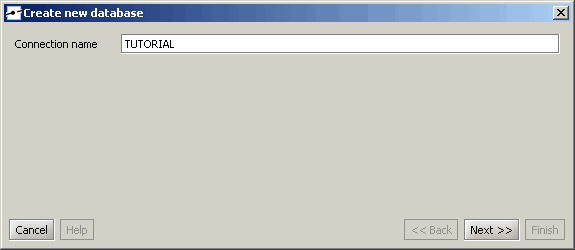
Verwenden Sie die „Weiter >>;“ Taste, um fortzufahren. Jetzt fragt der Dialog nach dem Typ der Verbindung.
Verwenden Sie „Vordefinierte JNDI-Datenquelle verbinden“, um die vordefinierte Datenquelle wie zuvor beschrieben zu verbinden.
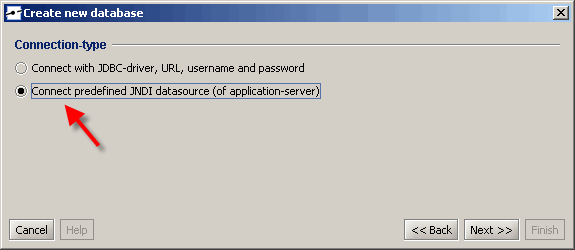
Wählen Sie die gewünschte vordefinierte Datenquelle auf dem folgenden Bildschirm aus. Es gibt drei Datenquellen in der Standardinstallation von instantOLAP, wir verwenden die Quelle „java: comp/env/jdbc/TutorialDS“ (dies ist die Standardnotation für Datenquellen in Java, sogar auf verschiedenen Anwendungsservern).
Verwenden Sie dann „Weiter >>“ Schaltfläche, um zum letzten Bildschirm des Datenbankassistenten zu gelangen. Hier können Sie das Schema und den Katalog festlegen. Da die HSQL-Datenbank dies nicht unterstützt, bleiben beide Selektoren leer und Sie können den Assistenten mit der Schaltfläche „Fertig stellen“ beenden.
Nachdem Sie die Datenquelle erstellt haben, können Sie deren Inhalt untersuchen. Die neue Datenquelle wird im Explorer am linken Rand der Workbench angezeigt. Öffnen Sie es auch, um seine Tabellen und ihre Spalten zu sehen. Sie können auch einige SQL-Anweisungen ausführen oder den Inhalt einer Tabelle anzeigen, indem Sie das Kontextmenü der Datenquelle oder ihrer Tabellen verwenden.
Produktdimension erstellen
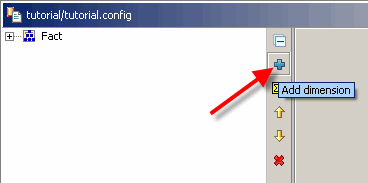
Der Dimensionsassistent wird angezeigt. Hier können Sie den Namen der neuen Dimension und den Namen (id) ihres ersten Mitgliedsschlüssels angeben.
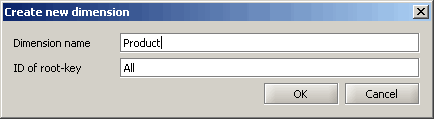
Ändern Sie den Dimensionsnamen in „Produkt“. Dies ist die erste Dimension in Ihrer Konfiguration. Der Name des Stammschlüssels (standardmäßig „Alle“) kann unverändert gelassen werden (der Stammschlüssel ist der oberste Schlüssel innerhalb einer Dimension).
Klicken Sie auf „OK“ und validieren Sie die Definition Ihrer neuen Dimension im Dimensionseditor, indem Sie sie im Dimensionsbaum öffnen.

Dies ist die einfachste mögliche Dimension, die nichts anderes als den obligatorischen Stammschlüssel enthält.
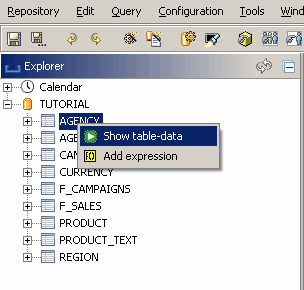
Da wir mehr Mitglieder innerhalb der Produktdimension benötigen, importieren wir Daten aus der Datenbanktabelle „PRODUCT“ in die neue Dimension. Um einen Loader dafür zu erstellen, öffnen Sie die PRODUCT-Tabelle im Explorer (am linken Rand der Workbench) und ziehen deren Spalte „PRODUCT_NO“ auf den Root-Key der Dimension. Nachdem Sie die Spalte gelöscht haben, wird ein neuer Loader unter dem Stammschlüssel angezeigt. Nun wird für jeden Wert in der Spalte
PRODUCT_NO ein Schlüssel generiert und unter dem Stammschlüssel der Dimension platziert.
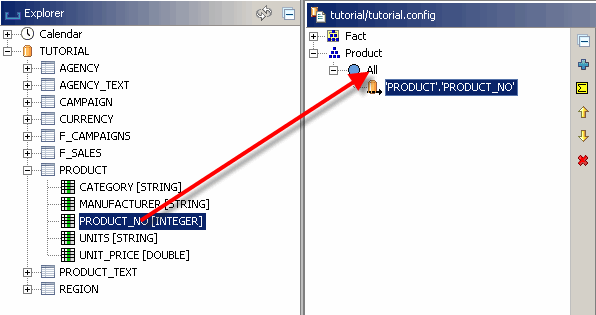
Sie können die Bemaßung mit der grünen Vorschautaste im unteren Fenster des Bemaßungseditors erstellen.
Nachdem die Dimension erstellt und geladen wurde, können Sie ihre Schlüssel hier untersuchen.
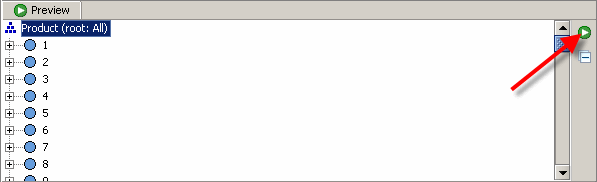
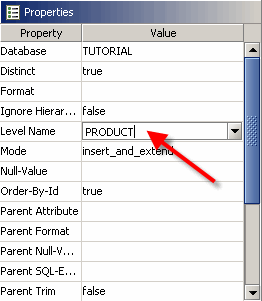
Nach dem Generieren der ersten Schlüssel der Dimension sollten Sie der neuen Ebene in der Dimension einen Namen zuweisen. Wählen Sie dazu den neuen Key-Loader aus und ändern Sie seine Eigenschaften im Eigenschaften-Editor unten links in der Workbench. Für jeden Key-Loader gibt es eine Eigenschaft namens „Level Name“, die leer ist, nachdem ein neuer Loader erstellt wurde. Ändern Sie nun den Namen in „PRODUKT“ und bestätigen Sie Ihre Änderung durch Drücken der Eingabetaste.
Jetzt ist die erste Dimension Ihrer Konfiguration beendet.
Eine neue Tatsache hinzufügen
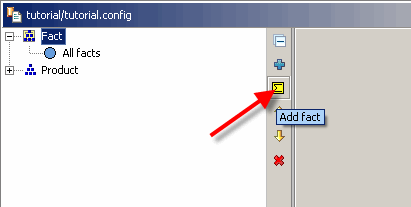
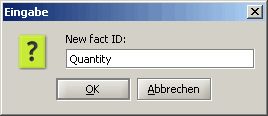
Dies öffnet den Fakten-Assistenten, in dem Sie den Namen der neuen Tatsache definieren können. Wählen Sie als Namen „Menge“.
Die neue Tatsache wird als neuer Schlüssel innerhalb der Fakt-Dimension erscheinen. Die Faktendimension ist eine verbindliche Dimension, die alle Fakten als Schlüssel enthält. Öffnen Sie die Faktendimension im Dimensions-Tab, um die neue Tatsache zu sehen.
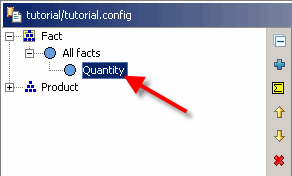
Erstelle einen Würfel
Verwenden Sie die neue Schaltfläche „SQL-Cube hinzufügen“ der Symbolleiste, um den ersten Cube zur Konfiguration hinzuzufügen (ein SQL-Cube lädt den Wert für Fakten aus SQL-Datenbanken). Eine neue Spalte wird im Cube-Editor angezeigt. Der fettgedruckte Titel des neuen Würfels zeigt die Datenbank an, mit der dieser neue Würfel verbunden ist (da es nur eine Datenquelle gibt, müssen Sie sie nicht ändern).
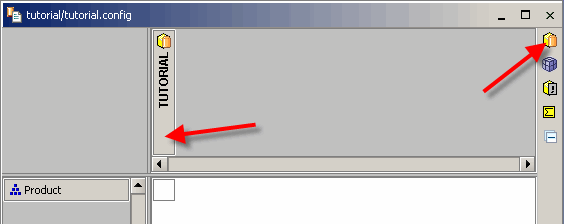
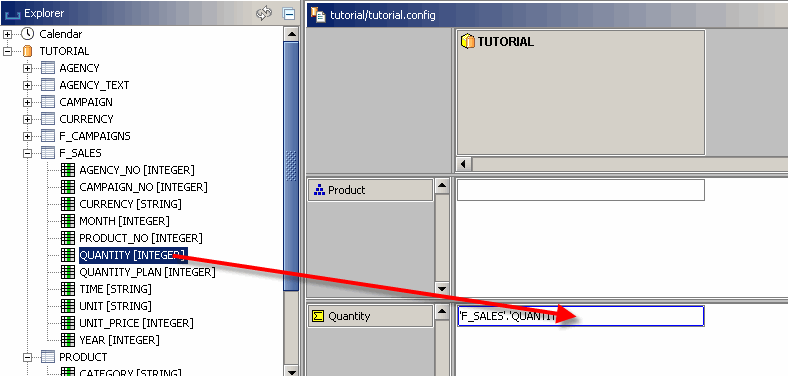
Jetzt können Sie den neuen Cube mit der Faktentabelle aus der Datenbank verbinden. Zunächst können Sie die Spalte mit dem Wert der Tatsache „Menge“ auswählen, indem Sie sie in die Zelle der Faktenzeile ziehen. Die Faktentabelle der TUTORIAL-Datenbank ist die Tabelle „F_SALES“,
die Betrags-Spalte heißt „QUANTITY“.
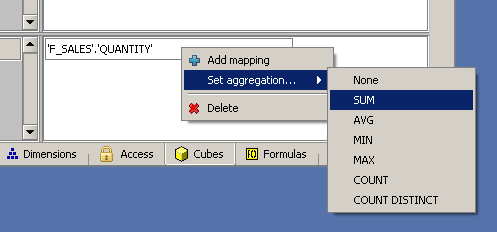
Sie müssen auch die Aggregation für diese Tatsache definieren, die beim Laden von Daten aus der Datenbank als Aggregation verwendet wird. Verwenden Sie die rechte Maustaste in der Zelle der Zelle, um das Popup-Menü zu öffnen, und wählen Sie „Set aggregation … / SUM“, um die Aggregation auf „SUM“ zu setzen.
Nach der Verknüpfung müssen alle Dimensionen, von denen diese Tatsache abhängt, abgebildet werden. In diesem Fall ist dies nur die Produktdimension.
In der Tabelle F_SALES gibt es einen Spaltennamen „PRODUCT_NO“, der die ID des verkauften Produkts enthält.
Ziehen Sie diese Spalte auf die Zelle des Cubes, die der Produktdimension entspricht.
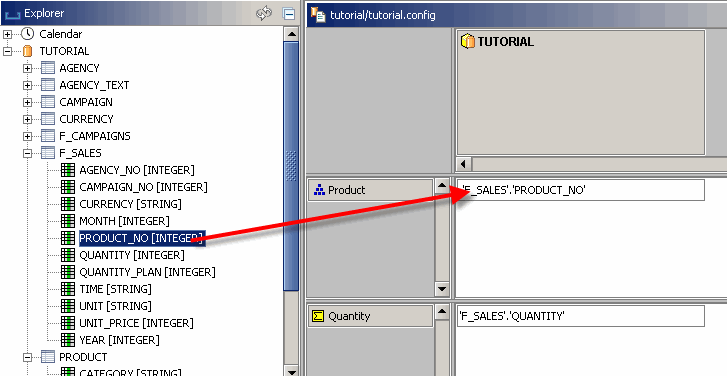
Jetzt ist jeder Datensatz der Verkaufstabelle über seine ID mit einem Produkt verbunden.
Speichern Sie die Konfiguration
Die erste Version Ihrer Konfiguration ist fertig und Sie können Ihre erste Abfrage erstellen.
Bevor Sie jedoch eine neue Abfrage erstellen, müssen Sie die Konfiguration speichern, um sie für Abfragen über die Schaltfläche „Speichern“ der
Workbench-Symbolleiste sichtbar zu machen.
Erstellen der Abfrage
Neue Abfragedatei erstellen
Das Erstellen einer neuen Abfrage ähnelt dem Erstellen einer Konfiguration. Verwenden Sie die Schaltfläche „Neue Abfrage“ im Kontextmenü Ihres Ordners. Nach der Verwendung des Menüeintrags wird ein neuer Assistent angezeigt.  Beim Erstellen eines neue Abfrage müssen Sie einige obligatorische Informationen im Assistenten angeben. Die wichtigste Einstellung ist der Cube, auf dem die Abfrage basieren soll. Der Assistent wählt die erste Konfiguration im gleichen Ordner wie die Standardkonfiguration aus. Da sich nur eine im Ordner befindet, können Sie die ausgewählte Konfiguration auswählen und auf „Next >>“ button.
Beim Erstellen eines neue Abfrage müssen Sie einige obligatorische Informationen im Assistenten angeben. Die wichtigste Einstellung ist der Cube, auf dem die Abfrage basieren soll. Der Assistent wählt die erste Konfiguration im gleichen Ordner wie die Standardkonfiguration aus. Da sich nur eine im Ordner befindet, können Sie die ausgewählte Konfiguration auswählen und auf „Next >>“ button. 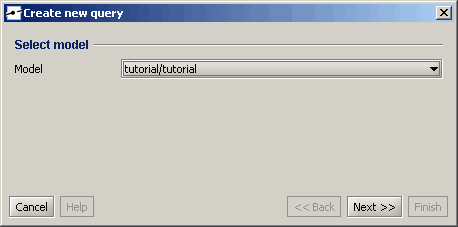
Sie können auch den Dateinamen, den Namen (dies ist der Kurzname einer Abfrage, die in der Navigation angezeigt wird) und den Titel (der bei der Ausführung als Titel einer Abfrage angezeigt wird) festlegen. Ändern Sie den Dateinamen nur in „lesson1.query“.
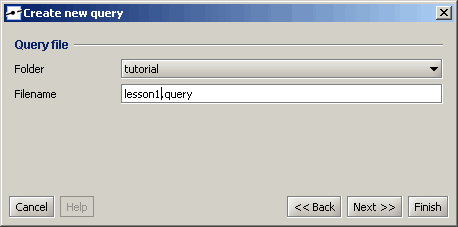
Nachdem Sie die Schaltfläche „Fertig“ verwendet haben, wird ein neues Fenster geöffnet, in dem der Abfrageeditor angezeigt wird.
Fügt der Pivot-Tabelle einen Fakt hinzu
Die neue Abfrage enthält standardmäßig eine leere Pivot-Tabelle ohne Header in der X- oder Y-Achse. Sie können neue Kopfzeilen (die die Zeilen und Zellen Ihrer Abfrage definieren) hinzufügen, indem Sie sie aus dem Modell-Explorer oben links in der Workbench ziehen. Fakten werden als kleines gelbes Rechteck (das ein Zusammenfassungszeichen enthält) im Explorer angezeigt, nachdem Sie die Dimension „Fakt“ geöffnet haben – dort sollten Sie die Tatsache sehen, die „Menge“ genannt wird.
Ziehen Sie diesen Umstand in die leere Kopfzeile an der X-Achse (wo der Text „Spalten hier ablegen“ angezeigt wird).
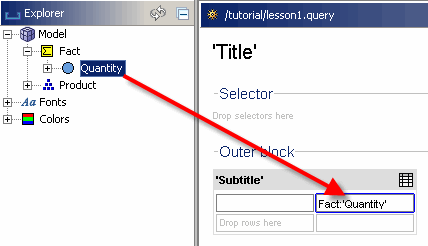
Der neue Header wird jetzt in die X-Achse Ihrer Tabelle eingefügt und generiert eine Spalte, wenn die Abfrage ausgeführt wird.
Hinzufügen einer Dimension zur Pivot-Tabelle
Neben der Tatsache in der X-Achse wollen wir auch Zeilen erzeugen – z.B. eine Zeile für jedes Mitglied in unserer Produktdimension gespeichert. Doppelklicken Sie im Modellexplorer auf die Produktdimension, um sie zu öffnen und deren Inhalt anzuzeigen. Jetzt können Sie den Wurzelschlüssel der Dimension, ihre Ebenen und einige vordefinierte Formeln sehen (und öffnen) (Formeln werden als kleine gelbe Rechtecke mit einem „f ()“ angezeigt).
Die Ebene „PRODUKT“ der Produktdimension wird mit dem Ebenensymbol (mit drei Punkten hintereinander) angezeigt. Ziehen Sie nun diese Ebene auf die Y-Achse Ihrer Pivot-Tabelle.
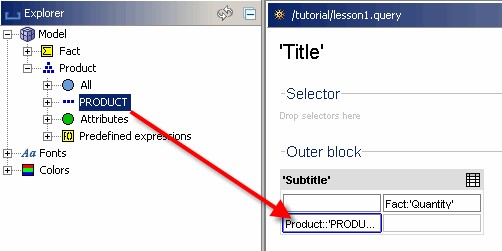
Im Gegensatz zu der Tatsache, die Sie zuvor zur Tabelle hinzugefügt haben, erstellt dieser neue Header nicht nur einen einzigen Header, sondern einen Header für jedes einzelne Produkt, das in der Produktdimension gespeichert ist.
Testen Sie Ihre Suchanfrage
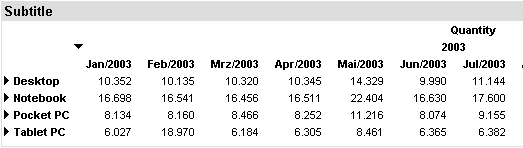
Jetzt ist Ihre erste Abfrage abgeschlossen. Sie zeigt für jedes Produkt eine Zeile und eine Spalte mit der Angabe „Menge“ an. Verwenden Sie die Registerkarte „Vorschau“ am unteren Rand des Editors, um die Abfrage auszuführen und das Ergebnis in der Vorschau anzuzeigen.
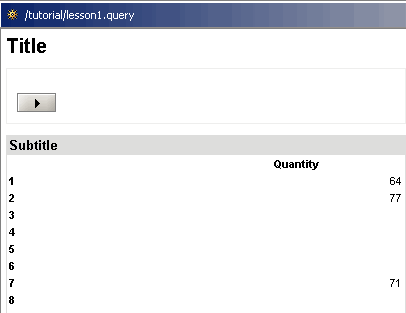
Da nicht für jedes einzelne Produkt Daten in der Faktentabelle gespeichert sind, sind einige der Zeilen leer. Außerdem werden die Produkte mit ihren technischen IDs angezeigt, da die IDs zum Generieren der Dimension verwendet wurden. Die folgenden Lektionen zeigen, wie die Produktnamen anstelle ihrer IDs angezeigt werden und wie die leeren Zeilen unterdrückt werden.
Speichern Sie Ihre Suchanfrage
Vergessen Sie nicht, Ihre Anfrage zu speichern, bevor Sie Ihre Arbeit fortsetzen. Wie im Konfigurationseditor zuvor können Sie die Abfrage mit der Schaltfläche „Speichern“ der Workbench speichern.
Ab instantOLAP 3.0 können Sie ganz einfach Berichte in Ihrem Browser erstellen. So einfach wie Excel-Pivot. Siehe auch Cantor ERP Beispiel
Lektion 2: Hinzufügen eines Anzeigetextes zum Dimenson
Verknüpfen von Tabellen
In der Tutorial-Datenbank wird der Text für die Produkte in einer anderen Tabelle als die Produkte gespeichert. Es gibt eine Tabelle mit dem Namen „PRODUCT_TEXT“, die die ID eines Produkts und seinen Text (sowohl einen Kurz- als auch einen Langtext) enthält.
Da der Text in einer zweiten Tabelle gespeichert ist, muss das System wissen, wie diese beiden Tabellen miteinander verbunden (verbunden) sind. In instantOLAP müssen Sie >> Verbindungen zwischen zwei Tabellen definieren, wenn Sie sie im gleichen Keyloader oder SQL-Cube verwenden möchten.
Der einfachste Weg, zwei oder mehr Tabellen zu verbinden, ist die Verwendung des ERM-Diagrammeditors des Konfigurationseditors. Öffnen Sie die Konfiguration und wechseln Sie zum Datenquellen-Tabulator, um das ERM-Diagramm anzuzeigen. Anfangs ist dieses Diagramm leer, weil es nur die Tabellen anzeigt, in die Sie zuvor gezogen haben (aber Sie können noch andere Tabellen verwenden, auch wenn sie nicht im ERM enthalten sind).
Um Tabellen zum Diagramm hinzuzufügen, öffnen Sie die Datenbank im Datenbank-Explorer (am linken Rand der Workbench) und ziehen sie einfach auf das Diagramm. Für unser Beispiel müssen Sie die Tabellen „PRODUCT“ und „PRODUCT_TEXT“ in das Diagramm ziehen.

Nein, Sie können einen Join zwischen den beiden Tabellen definieren, indem Sie eine Zeile von der Quellspalte in die Zielspalte „zeichnen“. In diesem Beispiel ist die Quellenspalte die Spalte „PRODUCT_NO“ der Tabelle „PRODUCT“ und die Zielspalte ist die Spalte „PRODUCT_NO“ der Tabelle „PRODUCT_TEXT“.
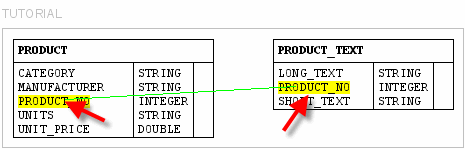
Nachdem Sie die Spalten verbunden und die Maustaste losgelassen haben, wird ein Fenster geöffnet, in dem Sie die Verknüpfung verfeinern können. Auf der ersten Seite können Sie den Namen des Links ändern (jeder Link muss einen eindeutigen Namen haben).
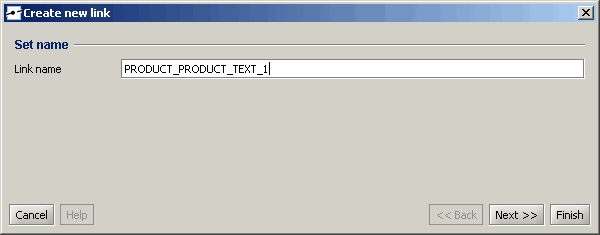
Auf der folgenden Seite sehen Sie die Quell- und Zieltabelle Ihres Links, wie Sie sie mit der Maus definiert haben. Auch die Richtung und der Typ der Verknüpfung sind hier änderbar (Joins können in instantOLAP unidirektional oder bidirektional sein, Sie können auch äußere Joins definieren, indem Sie den Typ ändern).
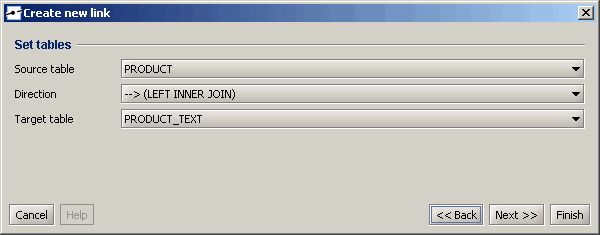
Auf der letzten Seite können Sie die Spalten des Links ändern. Sie können Ihrem Link auch weitere Spalten hinzufügen, wenn der Primärschlüssel der Tabellen aus mehr als einer Spalte besteht.
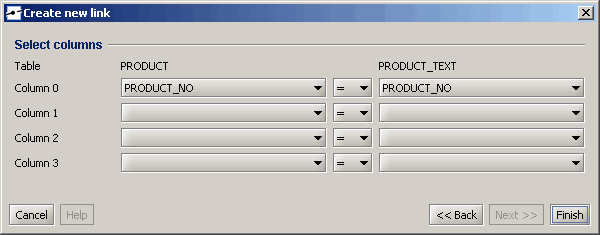
Verwenden Sie dann die Schaltfläche „Fertig stellen“, um den Join zu Ihrem ERM-Diagramm hinzuzufügen. Wenn Sie keine Eigenschaft des Links ändern möchten, können Sie den Link auch auf der ersten Seite des Assistenten beenden.
Ein Attribut zur Produktdimension hinzufügen
Da wir in der vorherigen Lektion bereits einen Loader für die Produkte erstellt haben, müssen wir nur die Spalten als Attribute zum vorhandenen Loader hinzufügen. Navigieren Sie zum Loader im Dimensionsbaum und wählen Sie ihn aus – dann sehen Sie in der rechten Hälfte des Konfigurationseditors eine leere Tabelle mit Attributdefinition.
Ziehen Sie nun beide Spalten auf die Tabelle, um sie als Attribute zu definieren. Wenn Sie die Spalten ziehen, zeigt der Mauszeiger an, wann das Löschen der Spalten möglich ist.
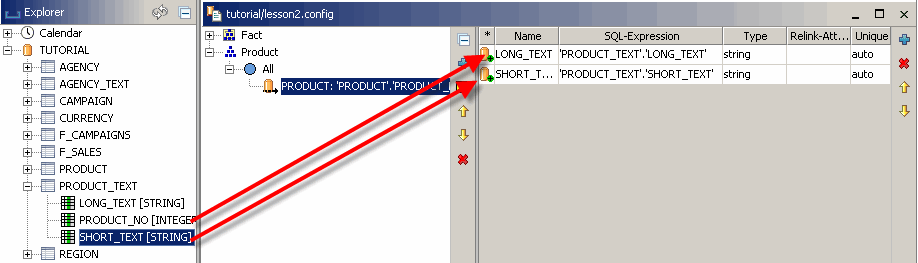
Wenn Sie die Vorschau für die Dimension im unteren Vorschaufenster ausführen, sehen Sie jetzt die Attributwerte.
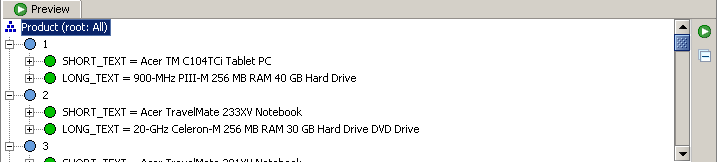
Standard-Textattribut für eine Dimension festlegen
Um das Standardtextattribut zu ändern, müssen Sie den Dimensionsknoten im Dimensionsbaum auswählen und die Eigenschaft „Standardtextattribut“ der Dimension bearbeiten. Mit dieser Eigenschaft können Sie eines der Attribute auswählen, die für die Dimension definiert wurden. Wählen Sie hier das Attribut „SHORT_TEXT“ aus.
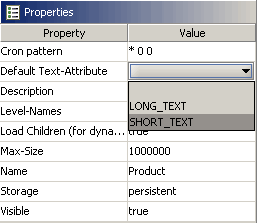
Wenn Sie die Abfrage der vorherigen Lektion erneut ausführen, sehen Sie, dass sich der Text der angezeigten Produkte von ihren technischen IDs zu ihrem Produktnamen geändert hat.
Lektion 3: Erstellen einer Dimension mit einer Hierarchie
Hinzufügen eines neuen Loaders für die zwei zusätzlichen Hierarchieebenen
Da wir die Dimension erweitern möchten, müssen Sie am unteren Rand des Editors in den Tabulator „Dimension“ wechseln. Öffnen Sie die Produktdimension, um die zugehörigen Loader anzuzeigen. Nun können Sie die Spalte „CATEGORY“ aus der Tabelle „PRODUCT“ auf den Stammschlüssel des Dimensionsstammschlüssels ziehen, wie Sie es in der ersten Lektion mit der Produktnummer gemacht haben.
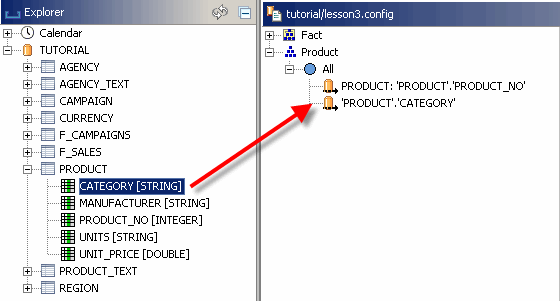
Durch Ziehen der CATEGORY-Spalte haben Sie jetzt die neue erste Ebene der Dimension erstellt. Der Produktloader, den wir in Lektion 1 erstellt haben, wird jetzt verdrängt, weil wir möchten, dass die Produkte unter den Kategorien liegen (jetzt würden sie auf derselben Ebene mit den Kategorien erscheinen). Das Ändern der Loader-Position ist ganz einfach: Ziehen Sie einfach den alten Loader auf den neuen Kategorie-Loader, um ihn dort zu kapseln.
Vergessen Sie nicht, dem neuen Loader einen Ebenennamen zuzuweisen, indem Sie ihn auswählen und die Eigenschaft „Ebenenname“ ändern, z. auf den Ebenennamen „KATEGORIE“.

Schließlich haben wir eine Produktdimension mit drei Ebenen erstellt (Root, Kategorie und Produkte). Verwenden Sie erneut das Vorschaufenster, um den Inhalt der Dimension zu überprüfen.
Dimensionsbindung im Würfel erweitern
In der vorherigen Version des Cubes war die Bindung einfach, weil unsere Faktentabelle in der Datenbank eine Spalte „PRODUCT_NO“ enthält, die exakt mit den Produktschlüsseln in unserer Dimension übereinstimmt. Jetzt möchten wir eine neue Bindung für die Kategorien hinzufügen, aber es gibt keine Kategorie-Spalte in unserer Faktentabelle. Daher müssen wir einen neuen Join zwischen der Faktentabelle und der Produkttabelle hinzufügen, um die Spalte „CATEGORY“ der Tabelle „PRODUCT“ für die neue Bindung zu verwenden.
Wie in der vorherigen Lektion können Sie die Faktentabelle „F_SALES“ in das ERM-Diagramm ziehen und mit der Maus mit der Tabelle „PRODUCT“ verknüpfen. Beachten Sie, dass Sie immer Links von der Faktentabelle zu der Dimensionstabellen definieren sollten.
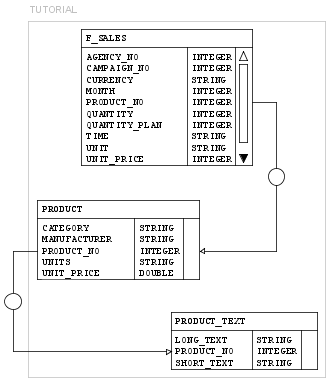
Jetzt können Sie im Konfigurationseditor in den Tabulator „Cubes“ wechseln und Ihrem Cube ein zweites Mapping für die Dimension „Product“ hinzufügen. Ziehen Sie dazu einfach die Spalte „CATEGORY“ aus der Tabelle „PRODUCT“ in die Dimensionszelle des Cubes und fügen Sie eine zweite Zuordnung hinzu.
Aber jetzt haben wir zwei verschiedene Mappings für dieselbe Dimension. Das Problem besteht darin, dass der Würfel nicht weiß, welche Zuordnung für welche Ebene der Dimension verwendet werden sollte. Um dies zu definieren, können Sie den Menüpunkt „Nur eine Ebene zuordnen …“ der Würfelzelle verwenden und die Ebene für ein Mapping definieren. Wählen Sie „PRODUCT“ für die erste und „CATEGORY“ für die neue Zuordnung – jetzt gibt es verschiedene Mappings für verschiedene Ebenen.
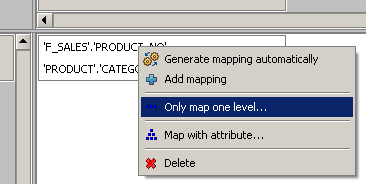
Nachdem Sie die neue Zuordnung hinzugefügt und ihre Ebenen definiert haben, sollte der SQL-Cube wie im folgenden Bild aussehen:
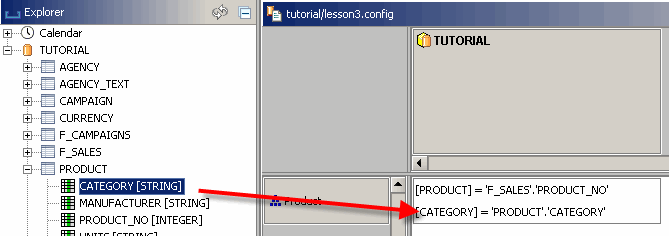
Drilldown zu Ihrer Suchanfrage hinzufügen
Testen Sie Ihre vorhandene Abfrage
Wenn Sie Ihre Abfrage erneut öffnen und erneut ausführen, werden die Produkte immer noch als Zeilen angezeigt, da in der vorherigen Definition der Abfrage das System angewiesen wurde, die Ebene mit dem Namen „PRODUCT“ auf der Y-Achse anzuzeigen. Obwohl sich das Niveau geändert hat und tiefer in die Hierarchie der Dimension einging, hat es immer noch den gleichen Namen.
Jetzt erstellen wir eine weitere Abfrage, die statt der Ebene „PRODUCT“ die Ebene „CATEGORY“ auf der Y-Achse anzeigt. Lassen Sie erneut die Angabe „Quantity“ auf die Achse fallen.
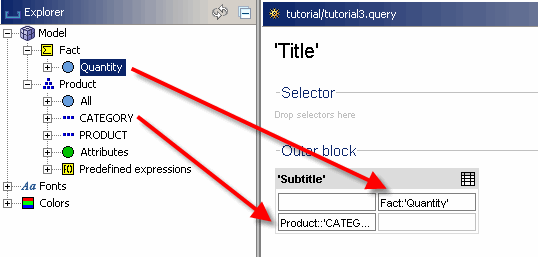
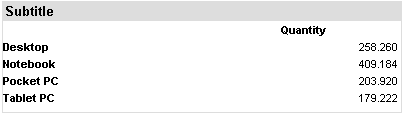
Wenn Sie diese Abfrage ausführen, sehen Sie, dass die Anzahl der Zeilen dramatisch abgenommen hat. Dies liegt daran, dass die neue erste Ebene unserer Dimension weniger Elemente als die Produktebenen enthält und unsere Abfrage diese neue Ebene der Dimension anzeigt.
Wie Sie auch sehen können, sind die Zellen immer noch mit Zahlen gefüllt. Dies sind die vom SQL-Cube aggregierten Daten, die eine SELECT-Anweisung unter Verwendung der Spalte „CATEGORY“ aus der Tabelle „PRODUCT“ als ihren GROUP BY-Ausdruck generiert haben.
Drilldown aktivieren
& gt; Es gibt zwei verschiedene Stile für den Drilldown in instantOLAP (vertikal und gekapselt), die sich in der Darstellung der neu geöffneten Kopfzeilen unterscheiden. Im ‚vertikalen‘ Stil werden die neuen Zeilen in der Tabelle, im ‚eingekapselten‘ Stil werden die Subheader ihres übergeordneten Headers.
Führen Sie nun die Abfrage erneut aus. Sie werden vor jedem Header kleine Dreiecke sehen. Dies ist die Drilldown-Schaltfläche für einen Header – wenn Sie darauf klicken, wird der Header erweitert und zeigt seine untergeordneten Elemente in der Pivot-Tabelle an:

Nachdem Sie in einen Header gebohrt haben, ändert sich das Symbol dieses Headers in ein anderes Symbol (das Drillup-Symbol), mit dem Sie den Header wieder schließen können.
Lektion 4: Hinzufügen einer Zeitdimension
In dieser Lektion erfahren Sie, wie Sie eine Kalenderdimension einrichten und wie Sie sie mit dem Würfel verbinden.
Hinzufügen der ZeitdimensionHinzufügen von Loadern
In der Faktentabelle gibt es zwei Spalten mit den Namen „YEAR“ und „MONTH“, mit denen wir die neue Dimension füllen können. Der elegantere Weg ist jedoch, den eingebauten Kalender von instantOLAP in unserer Zeitdimension zu verwenden. Die Verwendung des internen Kalenders bietet mehr Flexibilität und erzeugt keine Lücken für fehlende Monate in Ihrer Dimension (wenn Sie die Datenbank als Quelle verwenden würden, würden nur Monate mit Daten generiert).
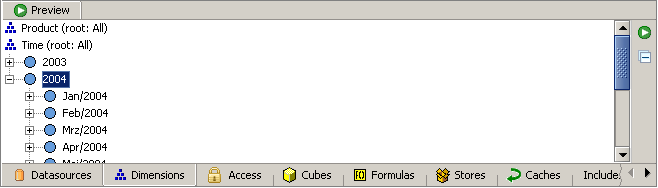
Wechseln Sie den Datenquellen-Explorer in der oberen linken Ecke in die Ansicht „Kalender“, indem Sie das Element „Kalender“ in der Auswahlliste auswählen. Jetzt können Sie eine Reihe von vordefinierten Zeitmustern für Ihre Verwendung sehen. Beginnen Sie mit dem Ziehen des Musters „yyyy“ (das für eine vierstellige Jahreszahl steht) auf den Stammschlüssel der Zeitdimension.
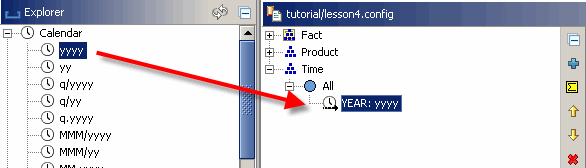
Vergessen Sie nicht, Ihrer neu erstellten Ebene einen Namen zu geben, z. Nennen Sie es „JAHR“.
Ziehen Sie dann das Muster „mmm/yyyy“ (das Monatsnamen kombiniert mit Jahren erzeugt) auf den soeben erstellten Jahresladeprogramm. Geben Sie Ihrem neuen Level erneut einen Namen, nennen Sie diesmal „MONAT“.
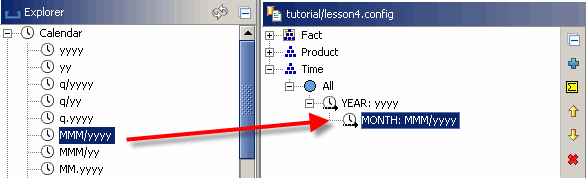
Einstellen der Zeitspanne
Wenn Sie die Dimension im Vorschaufenster öffnen, können Sie sehen, dass nur ein Monat generiert wird. Das liegt daran, dass wir den Bereich für die generierten Kalenderschlüssel nicht festgelegt haben und der Standardbereich von „jetzt“ bis „jetzt“ ist (also das einzige Jahr und der einzige Monat, den Sie sehen können, ist das aktuelle Jahr/Monat).
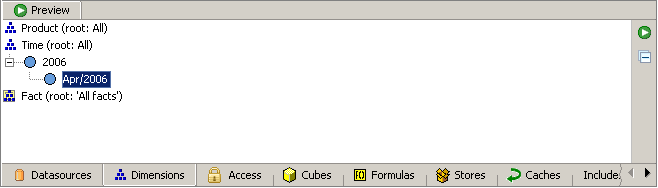
Die Tutorial-Datenbank enthält jedoch die Verkäufe für die Jahre 2003 und 2004. Klicken Sie auf den obersten Kalender-Loader, um dessen Eigenschaften im Eigenschaften-Editor zu sehen. Jetzt sehen Sie zwei Eigenschaften namens „Start“ und „Stop“ – der Zeitbereich muss hier definiert werden. Z.B. Setzen Sie „Start“ auf „01.01.2003“ und „Stop“ auf „31.12.2004“, um die Anzahl der Schlüssel festzulegen, die wir erstellen möchten (falls Ihr Land ein anderes Datumsformat hat, müssen Sie Ihr lokales Format verwenden).
Laden Sie nun die Dimension in der Vorschau neu und werfen Sie einen Blick in die Zeitdimension. Es sollte jetzt zwei Jahre (2003 und 2004) und zwölf Monate pro Jahr geben.
Attribute hinzufügen
Für das Level MONTH fügen wir nun ein Attribut mit einer technischen ID für den Monat hinzu, das an die Faktentabelle F_SALES gebunden werden kann. In der Faktentabelle gibt es eine Spalte „TIME“, in der der Monat durch einen Text im Format „MMyyyy“ identifiziert wird.
Wählen Sie zuerst den Loader für die Monatsebene aus, bis Sie seine Attribute im Bereich rechts neben dem Dimensionsbaum sehen. Fügen Sie nun dem Loader ein neues und leeres Attribut hinzu, indem Sie die Schaltfläche „Attribut hinzufügen“ am rechten Rand des Attributfensters verwenden – eine neue Zeile sollte erscheinen. Benennen Sie das Attribut „MonthID“, ändern Sie das Muster in „MMyyyy“ und setzen Sie den Typ auf „string“.
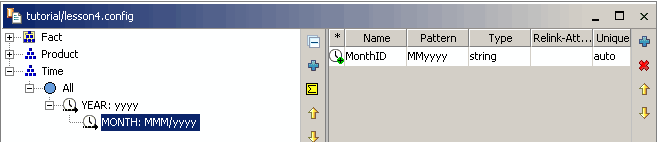
Wir haben den Kalender nicht aus dem Datenquellen-Explorer verwendet, da es kein vordefiniertes Format „MMyyyy“ gibt. Sie können das Attribut jedoch auch manuell erstellen und ein beliebiges Format verwenden oder ein anderes Format aus dem Kalender ziehen und das Muster anschließend ändern.
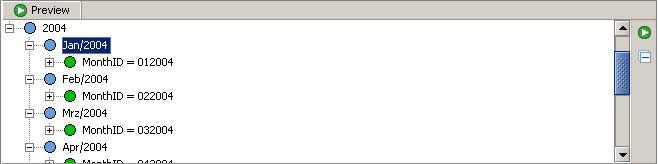
Wenn Sie die Zeitdimension in der Vorschau anzeigen, sollte jeder Monat eine eindeutige MonthID haben:
Verbinden Sie den Würfel mit der neuen Dimension
Die Tabelle „F_SALES“ enthält zwei Spalten „YEAR“ und „TIME“. Beginnen Sie, die erste dieser Spalte „YEAR“ auf die neue Zelle zu verteilen, die zur neuen Dimension gehört. Wie bei der Produktdimension zuvor müssen Sie diese Spalte über das Kontextmenü der Zelle einer einzelnen Ebene zuordnen und „YEAR“ als einzige zugeordnete Ebene auswählen.
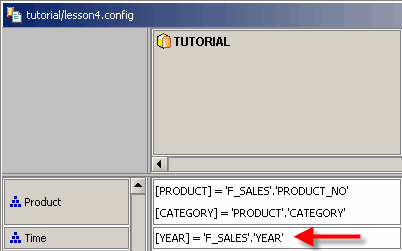
Ziehen Sie nun die Spalte „TIME“ in die gleiche Zelle – diese Spalte enthält Werte, die dem Attribut „MonthID“ der Zeitdimension entsprechen, aber es stimmt nicht mit einem Schlüssel der Dimension überein. Daher müssen Sie das System anweisen, die Spalte einem Attribut zuzuordnen, anstatt die Zuordnung auf eine einzige Ebene zu beschränken.
Öffnen Sie dazu das Kontextmenü des neuen Mappings und benutzen Sie den Menüpunkt „Map with attribute …“ und wählen Sie das Attribut „MonthID“ aus (dies sollte bis jetzt das einzige auswählbare Attribut sein).
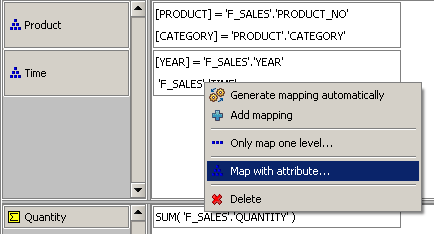
Jetzt haben Sie die beiden Ebenen unserer neuen Zeitdimension zugeordnet und können die neue Dimension in Ihren Abfragen verwenden.
Verwenden der Zeitdimension in Ihrer Abfrage
Wie bei den Produkten sollten Sie die Zeitdimension öffnen und die Ebene „JAHR“ unter den Faktenheader ziehen.
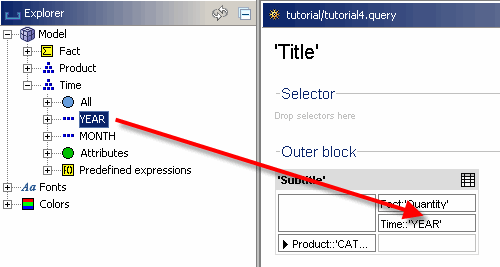
Wechseln Sie nun in den Vorschaumodus und schauen Sie nach. Die Tabelle sollte jetzt zwei Spalten haben, eine für jedes Jahr.
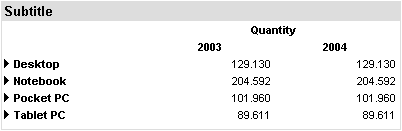
Wie in der vorherigen Lektion können Sie auch Drilldown zum neuen Monatskopf hinzufügen. Verwenden Sie erneut das Kontextmenü des Headers, um den Drilldown zu aktivieren, z. Verwenden Sie dieses Mal den „gekapselten Drilldown“.